

Because of the current hyperbole about Artificial Intelligence, an extract from the yet unpublished chapter of the book, The Entanglement of Being, has been brought forward, as an extract. So far, the book has only been published on Medium up to Chapter 8. The extract uses a number of unpublished parts of the book, but enough is included to explain how the various parts fit together.
Are Large Language Models Artificially Intelligent?
To discuss Large Language Models in the context of human cognition, it is useful to refer to a behavioural model of a normal human being. It is suggested that a reasonable behavioural model can be developed by combining the ideas of the CEST (Cognitive-Experiential Self-Theory), a dual-process psychological model of perception developed by Seymour Epstein in the 1990’s (Wikipedia on Cognitive-experiential self-theory, 2024), with some of the author’s amendments to and pruning of the ideas put forward in Zoltan Torey’s 1999 book, The Crucible of Consciousness.
As a prompt to what is being addressed, one might consider the following Einstein quote:
‘I didn’t arrive at my understanding of the fundamental laws of the universe through my rational mind.’
— Albert Einstein
The CEST model postulates that our mind operates essentially with two information processing systems, called the “analytical-rational” and “intuitive-experiential”. It is a behavioural model and doesn’t try to relate the two systems to anything particular in the brain and, obviously, is a simplification of reality. The systems are independent of each other but operate in tandem in manifesting human behaviour. The following table summarises Epstein’s comparison between the two systems.

Comparison of CEST Rational and Experiential Systems
‘Epstein argues that within the context of day-to-day life, a constant interaction occurs between the two systems. Because the experiential system is fast, guided by emotion and past experience and requires little in terms of cognitive resources, it is especially equipped to handle the majority of information processing on a daily basis, all of which occurs outside of conscious awareness. This, in turn, allows us to focus the limited capacity of our rational system on whatever requires our conscious attention at the time.
….. The analytical-rational system is that of conscious thought. It is slow, logical, and a much more recent evolutionary development. The rational system is what allows us to engage in many of the behaviours that we consider to be uniquely human such as abstract thought and the use of language. …. This system is emotionless and can be changed relatively easily through appeals of logic and reason.’ (Wikipedia on Cognitive-experiential self-theory, 2024)
There is some resonance to a quotation from Fritjof Capra’s book, The Tao of Physics, which describes how rational knowledge is derived:
‘Rational knowledge is derived from the experience we have with objects and events in our everyday environment. It belongs to the realm of the intellect, whose function is to discriminate, divide, compare, measure and categorize. …… Rational knowledge is thus a sequence of abstract concepts and symbols, characterized by the linear, sequential structure which is typical of our thinking and speaking. (Capra, 1984, p. 14)
The other part of the model comes from a severe pruning of the ideas of Zoltan Torey about how the mind works, which, it should be noted, has no status in neurological science. In his 1999 book, Torey proposed that the whole mind, sitting above what he called the infra-human brain, works in a hemispheric fashion with meaning in the right hemisphere and words, as tokens for the meaning, in the left hemisphere in a “Language of Thought” model after Noam Chomsky and others.
The author has taken just a small portion of Torey’s analysis, without any physiological designation to hemispheres and made it just a part of how the analytical-rational system works, referring to it as the “work-a-day” intellect of the analytical-rational system. The rest of the brain is referred to as the main brain and houses the intuitive-experiential system, central nervous system processing and such operations that others have called the “Global Workspace” or an equivalent concept. Here, it is worth recalling, so that we don’t get carried away with “Artificial Intelligence”, that what we call the conscious mind, including the intellect, takes up just 5% of the brain’s total operation.
We will discuss the operation of this amalgamated model, which the author calls the “Intellect Interaction Behavioural Model” (IIB Model) in a little more depth, after discussing the current Large Language Models, such as ChatGPT. However, it is worth noting that in the IIB Model, the “work-a-day” intellect, includes the development, in itself, of the idea of episodic time and the abstract conscious conception of self. Also, the intuitive-experiential system in the IIB Model has much more depth than implied in the CEST model and spans both the conscious and unconscious aspects of the brain, with the conscious analytical-rational system just assisting and only taking control when allowed.
What this hybrid model does, which the CEST model doesn’t do, is yield additional insights into free will, self and consciousness that comes from putting it all together into an interaction model.
As we shall see in the following, the large language models have managed to be a simulacrum of the “work-a-day” intellect, but without the development of the idea of episodic time or the abstract conscious concept of self. Here we need to clearly distinguish between the LLMs and other AI systems that have front ends in the sensory world and are specifically designed for things like driving cars. In that situation they are mimicking, and perhaps improving on, the habitual part of the intuitive-experiential system, as outlined in the CEST model. In contradistinction, The LLMs are all abstract and only can take the context from the words, rather than the case of humans, where the words just express and help articulate the perception of the real-world/human context. If you like - in humans, meaning leads to words, whereas in the LLMs, words having attached meanings. Returning to the IIB Model, then, the LLMs don’t mimic the intuitive-experiential system, just some aspects of the analytical system. Nonetheless, they have been a remarkable achievement.
Neural networks with many layers have the potential for deep learning. The key to this learning in the most efficient way is a rule called backpropagation, which is similar to the chain-rule for differentiation (for those of us who can remember their mathematics).
‘Backpropagation is a smart way to update the weights in a neural network. It computes a gradient — the rate at which the output changes as the input changes. And just like you can more quickly climb a mountain by following the steepest slope, backpropagation follows the gradient to find the best weights more quickly. Backpropagation meant that the weights in a deep neural network with many layers could be learnt faster. But the computations were still rather onerous.’ (Walsh, 2025, p. 106)
So, the problem became the amount of processing necessary to achieve the learning, until it was realised that the GPUs, the graphic processors used for 3D video games, were ideally suited for the matrix calculations required in backpropagation.
‘The discovery would quickly add over a trillion US dollars to the market capitalisation of NVIDIA Corporation, the company with an 80% share of the GPU market. They are surely one of the luckiest companies ever. They found themselves, by chance, selling the shovels for the AI revolution’ (Walsh, 2025, p. 106)
The deep learning recipe was almost complete — backpropagation over deep neural networks, using GPUs to manage the computational load. In 2012, in an image recognition AI competition, an eight-layer neural network, called AlexNet, developed based upon the deep learning recipe, blitzed the field and this started the deep learning revolution.
However, an important further improvement was later developed. They are called “transformers”, which is a particular way of connecting the neurons in a neural network, which works especially well for sequential data, like text. Text occurs in a sequence and the order matters. The best neural network for sequential data is different from the best ones suited for things like images, which are two-dimensional, and the image can move about in the frame across different images.
The transformer architecture was first proposed in 2017 in a paper with the title: ‘Attention Is All You Need’. (Vaswani, 2017)
As their name implies, transformers transform: they change complex inputs into complex outputs, like in translation or a question into an answer, as they do in ChatGPT.
There are four steps of a transformer. The first step is to put the input into something that the computer can process, which is a sequence of numbers. It is called “tokenization”, where words are replaced by numbers and complex words are broken down into smaller parts with separate numbers. However, there is also the relationship between different words in language and their meanings, which has to be taken into account. This is done by a second step, called “encoding”. Toby Walsh in his book, The Short History of AI, illustrates why this is necessary with the example of the meaning of the word “queen”. “Queen” has a relationship to the word “king”, but also to the word “bee”. However, “bee” also has a relationship to “beetle”, but “queen” doesn’t. This is managed by not just having a scalar number as a token for a word, but by turning the token into a vector in a multidimensional space to manage these complexities. The vectors are represented mathematically by matrices in the computation. It also means that you get the vector for “king” being equal to the vectors sum of “queen” + (“man” — “woman”).
However, there are pitfalls, like sexism, that can creep in and an example Toby Walsh gives, is when the vector for “architect” + (“woman” — “man”) gives “hairdresser”. (Walsh, 2025, pp. 116–117)
The third step in a transformer is called “attention”, which is about the connections between words in a sentence and a particular body of text under consideration. The obvious case is pronouns which need to be linked to their referents in a sentence. This step also deals with ambiguities, such as where words can have different meanings and so the system needs to pick the right meaning. The final step of a transformer is “decoding”, which is changing the calculated result back from vectors into tokens.
Toby Walsh gives the following example of the relationships between words that are far apart in the text.
‘Consider a sentence like the following:
Alice knew that her work contained errors but she wasn’t going to point them out.
The pronoun “them” refers to the noun errors, while the pronoun “she” refers to the noun “Alice”. Both pronouns are a long way away from the nouns to which they refer. This is where the transformer architecture has an important role to play. It allows neural networks to to identify such long-range dependencies using a mechanism called attention.
It should not come as a surprise that we might need different neural architecture for different tasks. We know this already from the human brain. Speech and language are processed in frontal and temporal lobes, while vision is processed in the visual cortex. And these different areas of the brain have different neural structures.’ (Walsh, 2025, p. 112)
The lesson, for us, is that so much of language, we take to be especially human, can be reduced to computerised neural networks, which take our language and transform it into vectors in numerical form, does its calculations and turns it back again into words, in answer to the task that was set for the neural network.
The next major step in the development of AI was aggressively scaling up the models with much more data and computation. This was spearheaded, in 2018, by a company called OpenAI. It went through successively larger models, with larger datasets and larger numbers of parameters in the models (parameters are weightings automatically adopted and adjusted internally in the model as a result of progressive training on the datasets). The scaling up can be illustrated by the numbers of parameters that get created in the models. According to Walsh (2025, pp. 122–3), OpenAI’s GPT-1, in 2018, had an impressive 17 million, GPT-2, in 2019, had 1.6 billion and GPT-3, in 2020, had 175 billion. In March 2023, GPT-4 was released and is believed to have about 1.75 trillion parameters.
GPT stands for Generative Pre-trained Transformer.
‘”Generative“ means that the model can generate text. “Pre-trained” means that the model is pre-trained with no particular goal in mind other than to discover features in the training data. In this case, the model develops a general understanding of language, and is then finetuned for specific tasks such as answering questions, translating text or finishing sentences. And “Transformer” because the model has the transformer architecture.’ (Walsh, 2025, pp. 123–124)
In 2022, OpenAI also added a front end to GPT-3, which became ChatGPT, which stands for “Chatting with GPT”. It became the fastest growing app ever and by the second month had 100 million users.
‘The overall idea behind ChatGPT is simple. It’s like auto-complete on your phone, but on steroids. In the case of auto-complete, your phone has a dictionary of words and their frequencies. If you type the letters “APP”, then the auto-complete tells you that the most likely way to finish this word is “APPLE”. ChatGPT just takes this further. It is trained not on a dictionary of words but on a significant fraction of the web. This scale means that ChatGPT can finish not just the word but also the sentence — even the paragraph or page.
This description of large language models like ChatGPT as auto-complete on steroids, exposes a fundamental limitation. Such models are statistical. They’re not understanding language like you or I do. They have no underlying model of the world.
Because they are not saying what is true but what is probable, large language models struggle most with reasoning.’ (Walsh, 2025, pp. 126–127)
To get from GPT-3 to ChatGPT, OpenAI also included a further refinement to the model and that was reinforcement learning from human feedback.
‘There’s a training phase in which humans are repeatedly asked which of two possible outputs of the large language model they prefer. Human feedback ensures that appropriate values are incorporated into the model. If humans down-rank racist and sexist answers, then the model learns to output better answers.’ (Walsh, 2025, p. 157)
Of course, the other major problem with these large language models is that they make stuff up. They are just calculating answers from questions, based upon the training data absorbed into the models’ highly complex, weighted logarithmic architecture. This made-up stuff is called hallucinations, which, of course, is misleading, because there is no baseline from which the model’s responses veer. It is just operating within its limitations.
‘The model has no knowledge of what is true or false. It merely says what is probable. What is remarkable is how often what is probable happens to be true.’ (Walsh, 2025, p. 128)
‘What I take from the success of ChatGPT is that we’ve overestimated not machine intelligence but human intelligence. A lot of human communication is quite formulaic. We don’t engage our brains as often as we think we do. Much of what we say is formulaic. And these formulas have now been taught to computers.’ (Walsh, 2025, p. 132)
Here, I think, is where the confusion about AI comes in. We don’t understand the depth of human intelligence.
So, what are these AI — Large Language Models actually producing? My take is that they produce a circumscribed simulacrum of human intelligence, but with access to a far greater range of expertise areas than individual humans can encompass. That poses the first issue, which is that repeating documented expertise is not intelligence, but it does need intelligence to have been there for the expertise to be documented in the first place.
Humans, through language, mathematics, etc., learnt over the centuries to create a great intergenerational store of knowledge. Individuals are born, grow up and learn to participate within a social/material environment which has benefitted from the application of this knowledge, without which most of us would be fairly helpless. We can also access this storehouse to develop skills in a particular area and so contribute to the functioning of the society. AI systems, like LLMs, are an innovation where that store of knowledge (or the portion of it they are trained on) is given its own processing system, separate to humans directly accessing and utilizing the knowledge themselves in specific areas relevant or of interest to each individual. Thus, it provides a probabilistic modulated way to ask and receive answers from the storehouse.
In the end, though, the LLMs are circumscribed. They are limited to the documented knowledge in the intergenerational store, although they can follow paths set out to extend it, so far as that goes, such as in the well-known example of predicting protein structures. In this regard, to help understand how the LLMs are circumscribed, the author distinguishes three prime ways of knowing. The word prime is used to mean that it is only referring to non-subjective ways of knowing about events and processes in the world, not things like the arts or humanities (all knowledge is subjective, so we are talking about degrees here). Thus, there is, what is called, “Direct-Objective”, “Abstracted” and “Deep Intuitive” knowing. To help distinguish the first two, the example of a thrown stone is used in the table below.

Two of the Three Ways of Knowing
The Direct-Objective is direct sensorial (objective) knowing. The Abstracted knowing is understanding the patterns, principles or laws of events in the world, so that a deeper understanding of a phenomenon is available. Deep Intuitive knowing is the insight that comes to people like scientists, who are at the cutting edge of the field and, very occasionally out of the blue, see a path forward to a greater understanding. In the IIB Model, the Deep-Intuitive knowing primarily resides in the intuitive-experiential system. In terms of the “Prime Ways of Knowing”, the LLMs do not know, they just regurgitate Abstracted knowing and subjective knowledge that has been documented. There is no understanding.
In terms of the IIB Model, the LLMs are like a robotic version of the “work-a-day” intellect, but with restrictions in the rational area, because they have no agency, sense of self, empathy, etc., beyond what it might have mechanically absorbed, in a jumbled way, about what others may have responded/reasoned in various other situations. They do not possess the same processes for decision making, that is illustrated in the Action Stopwatch for the IIB Model
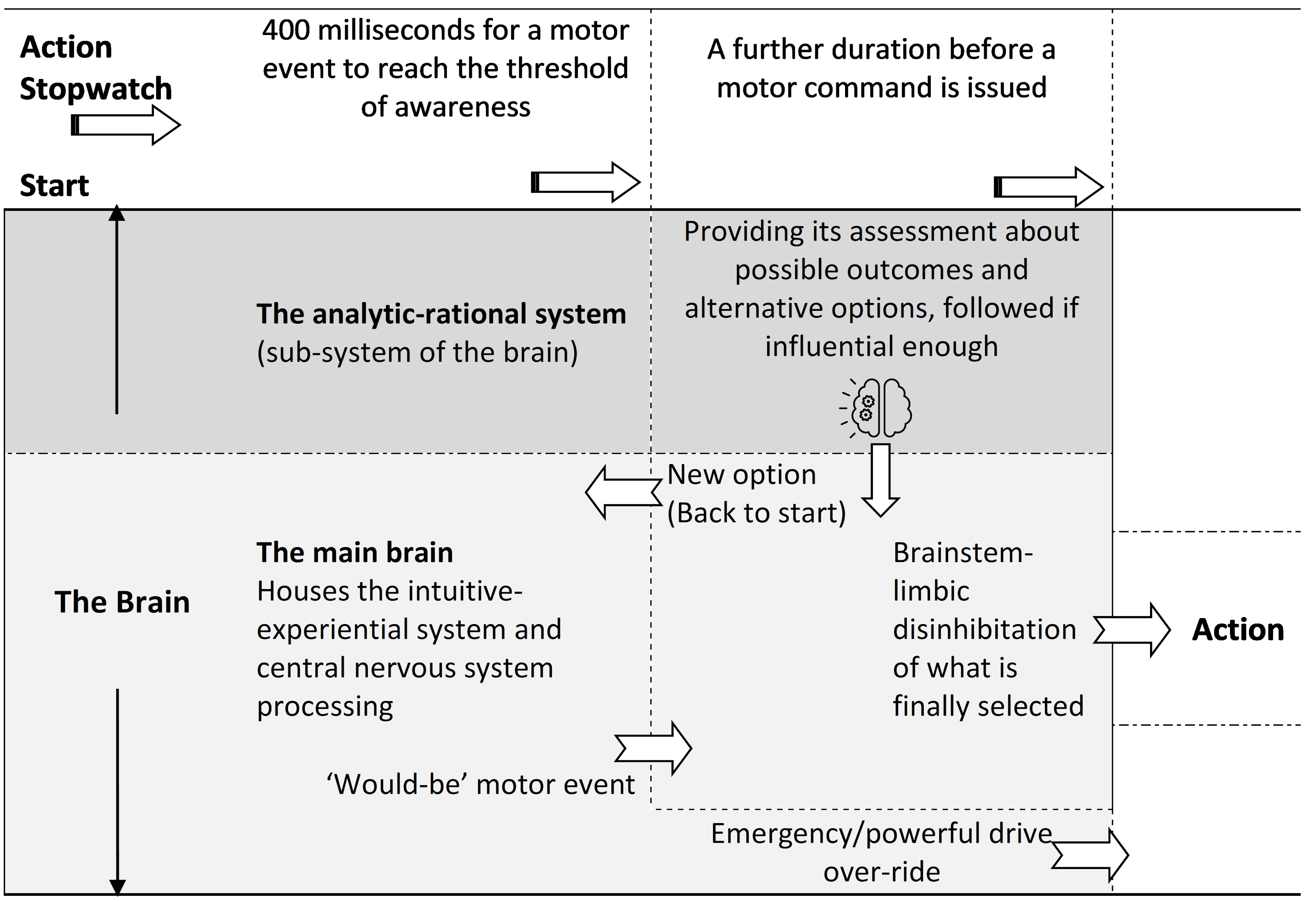
The Action Stopwatch in the IIB Model
The reader will note the brain icon with the mechanical geared wheels representing the input of the analytic-rational system. This represents the subsidiary nature of this system, which tries to get its view across and accepted. On this, Iain McGilchrist has come from an analysis of the characteristics of the hemispheres of the brain and notes:
‘In humans, just as in animals and birds, it turns out that each hemisphere attends to the world in a different way – and the ways are consistent. The right hemisphere underwrites breadth and flexibility of attention, where the left hemisphere brings to bear focused attention. This has the related consequence that the right hemisphere sees things whole, and in their context, where the left hemisphere sees things abstracted from context, and broken into parts, from which it then reconstructs a ‘whole’: something very different. And it also turns out that the capacities that help us, as humans, form bonds with others – empathy, emotional understanding, and so on – which involve a quite different kind of attention paid to the world, are largely right-hemisphere functions. (McGilchrist, 2009, pp. 27-28)
McGilchrist has pointed out that the focus on detail, while yet seeing the whole has not been a great success in the modern world, with the left hemisphere dysfunctionally dominating with its alarming self-confidence.
Thus, the LLMs are really just an unconscious, very well-informed, circumscribed probabilistic simulacrum of part of the conscious analytical-rational system, shown as part of the larger behavioural model in the diagram. They have mimicked the way the analytical-rational system has utilised language as it’s “thinking” (Language of Thought) tokens and put those tokens into its own mathematical formulation and processed them, circumscribed by the inherent limitations. This is because everything intelligent is missing, but the ability to make probabilistic recommendations and commentary. There is no guiding hand from the main brain of the intuitive-experiential system, which, in the end, decides what to lift the inhibition on for action, not the intellect.
So, bandying around the term artificial intelligence, pretending it matches or will be equivalent to human intelligence, is hyperbole. The current LLMs are more like automated, multi-disciplined, expert library assistant programs, that can pretty reliably access the details of what you are asking about, by having extracted it from the Abstracted and subjective knowledge storehouse, although it can’t remember all the book references. What they say can be prosaic, stunning, confused or nonsense.
LLMs are what they are, which is software. Software is not integrated with hardware like it is in humans, where it is one interactive system with awareness, qualia, interoception, proprioception, intellect, intuition and all the dynamic depth built in from millions of years of evolution.
References:
Capra, Fritjof, 1984, The Tao of Physics, 2nd Edition, Bantam New Age Books, Toronto
McGilchrist, Iain, 2009, The Master and His Emissary – The Divided Brain and the Making of the Western World, Yale University Press, New Haven and London, New Expanded Paperback Edition 2019. ISBN 978-0-300-24592-9
Torey, Zoltan, 1999, The Crucible of Consciousness — A personal exploration of the conscious mind, Oxford University Press, Melbourne (ISBN 0–19–550872–6)
Vaswani, Ashish et al., 2017, Attention is All you Need, NIPS’17 Advances in Neural Information Processing, 30, pp 6000–10
Walsh, Toby, 2025, The Shortest History of AI, Black Inc., Schartz Books, Collingwood, Aust.
Wikipedia, 2024, Cognitive-experiential self-theory, https://en.wikipedia.org/w/index.php?title=Cognitive-experiential_self-theory&oldid=1202553250
Me too. Ha.
Heavy stuff.. perhaps the quote from Albert Einstein does sum it up well:
“I didn’t arrive at my understanding of the fundamental laws of the universe through my rational mind.”